In Computer Science (CS) the freshman and sophomore years attrition rate can be as high as 40%, depending on institutes. The main reason behind this high attrition is lack of computational thinking ability, a must-have skill for a student to formulate a solution of a problem as computational steps or algorithms. In this research project, we are presenting a virtual reality assistant, which would provide one-to-one mathematics education at the elementary level with a focus on computational thinking. The broader impact of this research is to produce highly skilled computational thinking students, leading to a lower rate of CS attrition.
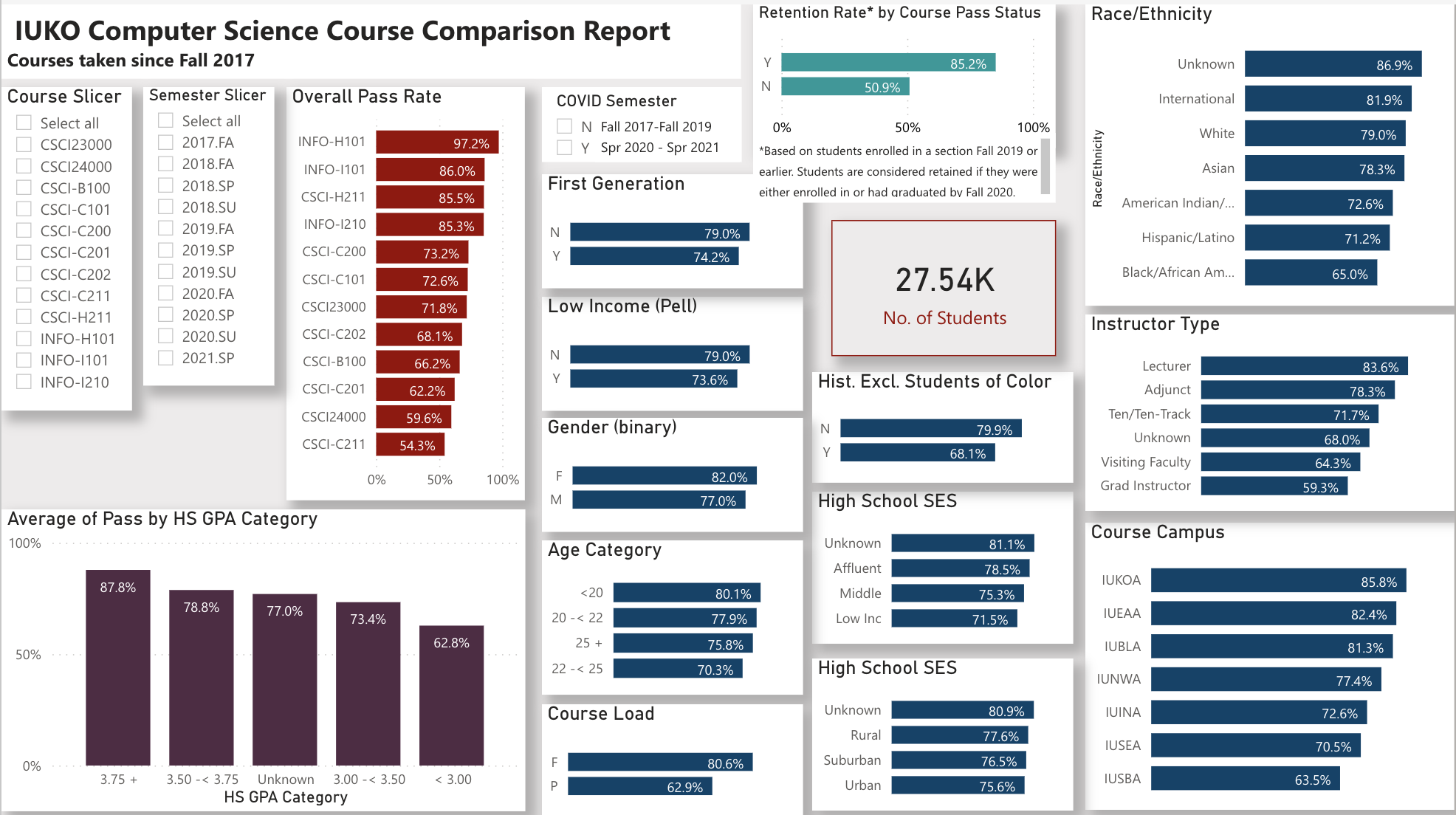
Higher attrition in CS is a matter that must be studied globally and addressed locally. This research was designed to investigate, identify, and mitigate the variables associated with higher attrition for the benefit of current and future students. The population of this study includes 27,540 students from twenty-three different courses offered at seven campuses across the state of Indiana. Through data analysis, several leading contributors to withdrawal are identified. However, some causes are ungovernable, interdisciplinary, and will open doors for future research.
CS Attrition and Retention
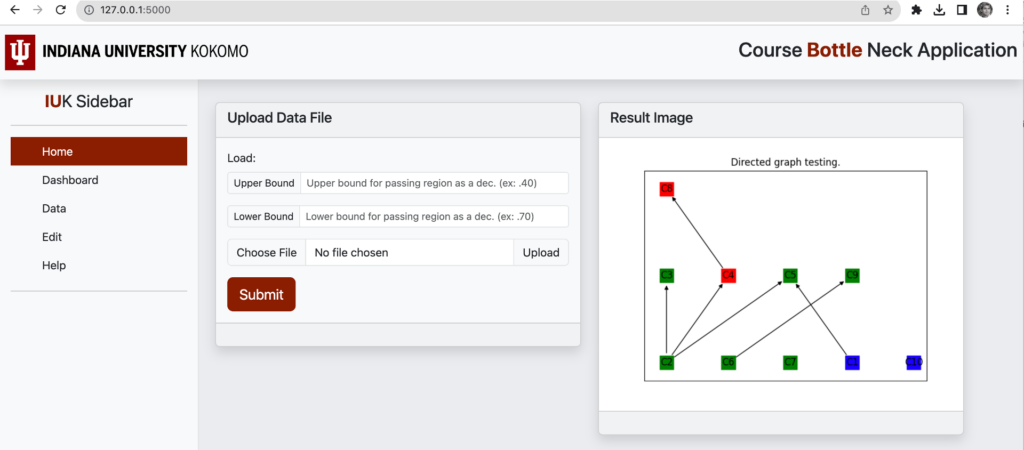
Identify Course Bottleneck
In this study, we examine the notion of course bottlenecks and their prevalence in various academic courses, particularly those in which a higher-than-average number of students experience failure. Subsequently, we delve into the features of a knowledge discovery software tool that has the capability to identify course bottlenecks and present the findings through a user-friendly graphical interface, accompanied by comprehensible explanations.
This project is generously supported by an NSF grant and represents an external collaboration between my laboratory and the DM research group at IUPUI. We have successfully implemented a web system, essentially a knowledge base, which presently houses over a thousand records, with its database expanding daily. One of the primary utilities of this knowledge base is to facilitate further research in the realms of computer science-related NLP and Deep Learning.
Our current research focus centers on the automatic extraction of phrases specific to the Computer Science domain. The inherent domain-specificity of these phrases sets our work apart from conventional phrase extraction techniques, rendering our task all the more challenging. Our forthcoming project will revolve around link prediction.